Dabbling with Spark Essentials
A Beginner's Guide to Using Apache Spark

Embarking on the journey of understanding Apache Spark marks the beginning of an exciting series designed for both newcomers and myself, as we navigate the complexities of big data processing together. Apache Spark, with its unparalleled capabilities in analytics and data processing, stands as a pivotal technology in the realms of data science and engineering. This series kicks off with "Dabbling into the Essentials: A Beginner's Guide to Using Apache Spark," an article penned from the perspective of someone who is not just a guide but also a fellow traveler on this learning journey. My aim is to simplify the intricate world of Spark, making its core concepts, architecture, and operational fundamentals accessible to all.
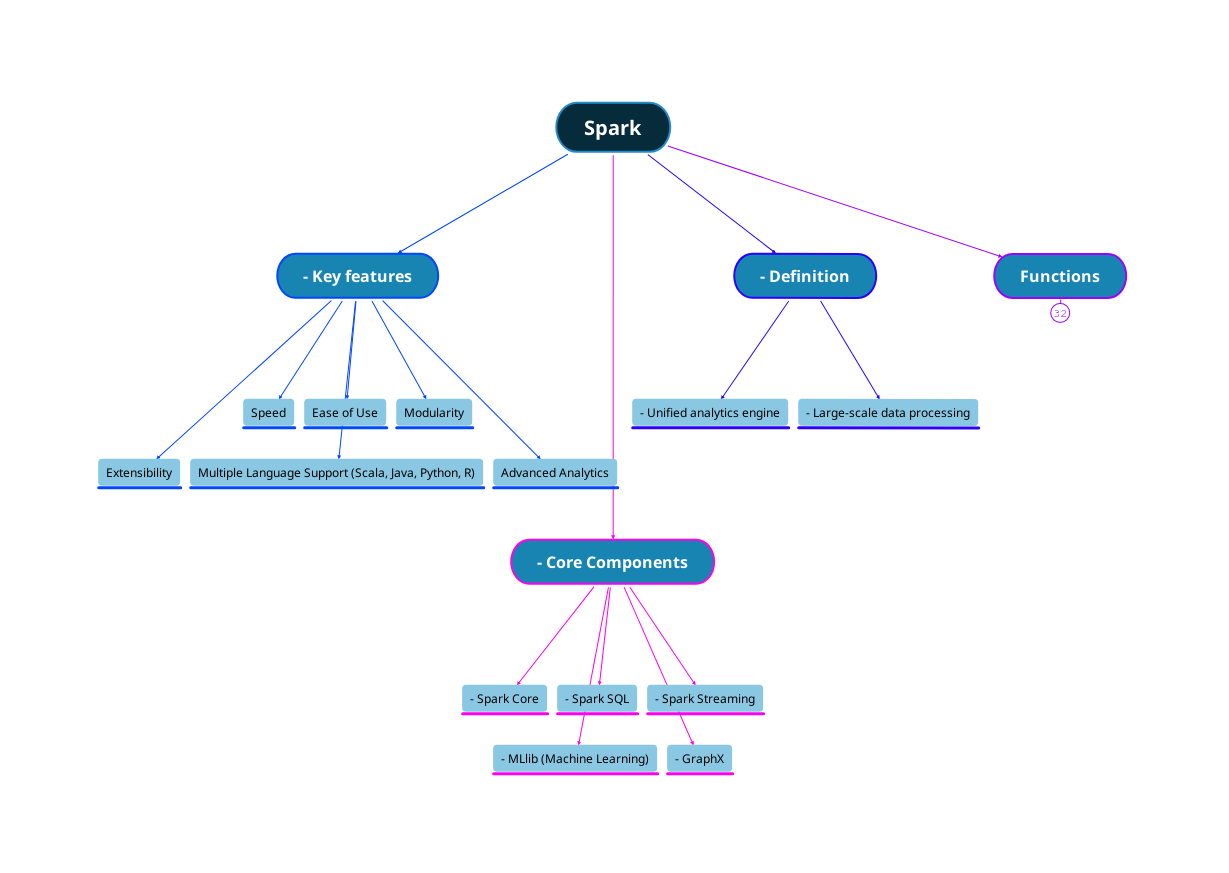
Core Concepts
At its heart, Spark is designed to efficiently process large volumes of data, spreading its tasks across many computers for rapid computation. It achieves this through several core concepts:
Resilient Distributed Datasets (RDDs)
Resilient Distributed Datasets (RDDs) are a fundamental concept in Spark. They are immutable distributed collections of objects. RDDs can be created through deterministic operations on either data in storage or other RDDs. They are fault-tolerant, as they track the lineage of transformations applied to them, allowing for re-computation in case of node failures. (Analogous to Git version tracking)
Directed Acyclic Graph (DAG)
Spark uses DAG to optimize workflows. Unlike traditional MapReduce, which executes tasks in a linear sequence, Spark processes tasks in a graph structure, allowing for more efficient execution of complex computations.
DataFrame and Dataset
Introduced in later versions, these abstractions are similar to RDDs but offer richer optimizations. They allow you to work with structured data more naturally and leverage Spark SQL for querying.
Key Features
Apache Spark is known for its remarkable speed, versatile nature, and ease of use. Here's why:
Speed
Spark's in-memory data processing is vastly faster than traditional disk-based processing for certain types of applications. It can run up to 100x faster than Hadoop MapReduce for in-memory processing and 10x faster for disk-based processing.
Ease of Use
With high-level APIs in Java, Scala, Python, and R, Spark allows developers to quickly write applications. Spark's concise and expressive syntax significantly reduces the amount of code required.
Advanced Analytics
Beyond simple map and reduce operations, Spark supports SQL queries, streaming data, machine learning (ML), and graph processing. These capabilities make it a comprehensive platform for complex analytics on big data.
Architecture
Apache Spark runs on a cluster, the basic structure of which includes a master node and worker nodes. The master node runs the Spark Context, which orchestrates the activities of the cluster. Worker nodes execute the tasks assigned to them. This design allows Spark to process data in parallel, significantly speeding up tasks.
Deployment
Spark can run standalone, on EC2, on Hadoop YARN, on Mesos, or in Kubernetes. This flexibility means it can be integrated into existing infrastructure with minimal hassle.
Use Cases
Real-Time Stream Processing: Spark's streaming capabilities allow for processing live data streams from sources like Kafka and Flume.
Machine Learning: Spark MLlib provides a suite of machine learning algorithms for classification, regression, clustering, and more.
Interactive SQL Queries: Spark SQL lets you run SQL/HQL queries on big data.
Getting Started
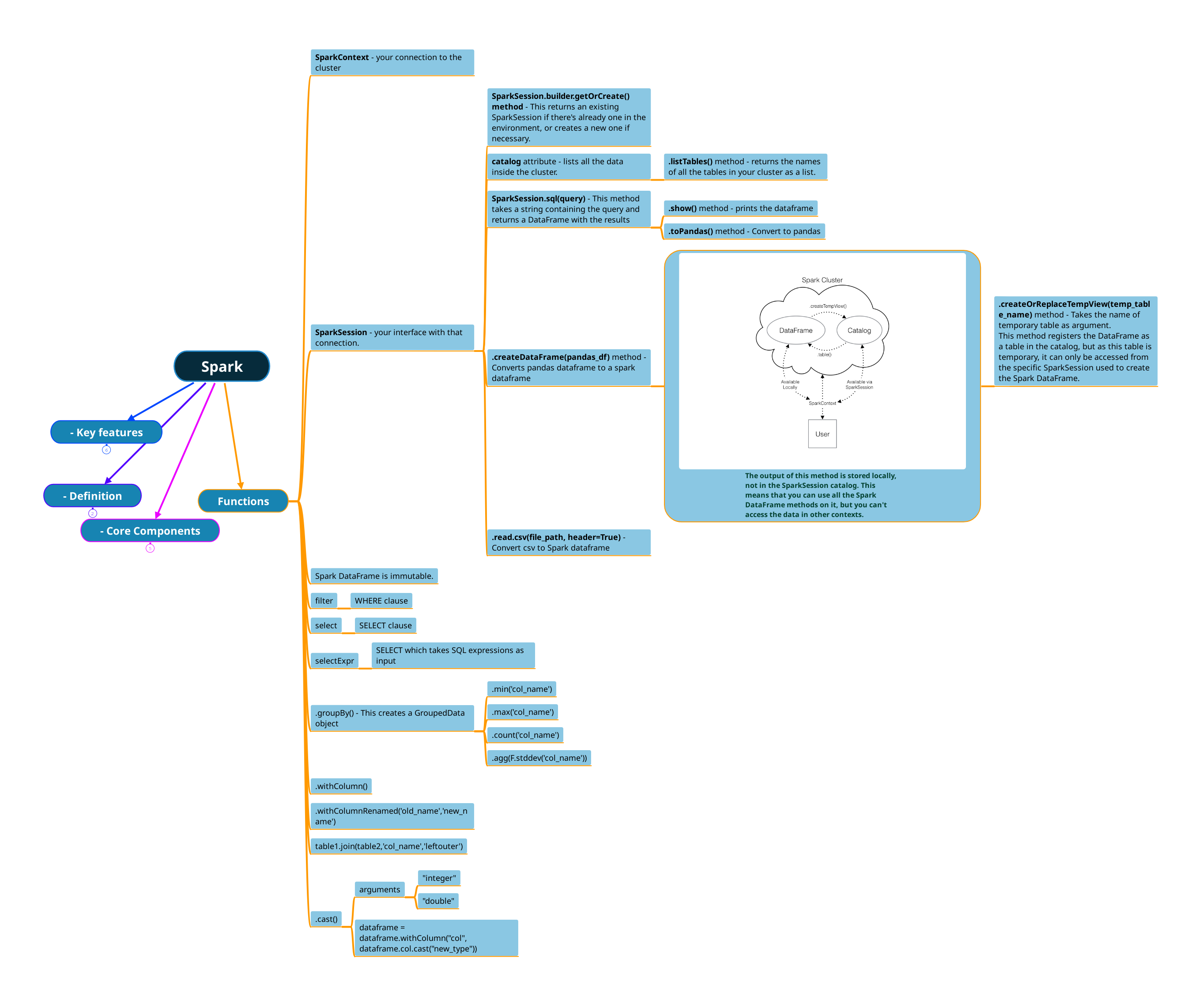
The map above lists the functions and methods used to perform basic operations in Pyspark. The code for each is listed in the headings below.
Understanding DataFrames and Catalogs
The image in the map above demonstrates the lifecycle and scope of data structures and components in a typical Spark application, focusing on how the user's code creates and interacts with DataFrames and how those relate to the Spark Cluster and the Catalog within a session.
The arrows show the relationships or interactions between these components:
The user creates and interacts with DataFrames locally in their Spark application through SparkContext.
The user can register DataFrames as temporary views in the catalog, making it possible to query them using SQL syntax.
The user can also directly query tables registered in the catalog using the
.table()method through the SparkSession.While the Catalog is accessed via SparkSession, the actual DataFrames are managed within the user's application and they interact with the cluster to distribute the computation.
Spark DataFrames are immutable, meaning once created, they cannot be altered. Any transformation creates a new DataFrame.
SparkContext and SparkSession
The SparkContext is the entry point to any Spark application, providing a connection to the Spark cluster, while the SparkSession offers an interface to that connection, enabling higher-level operations and easier interaction with Spark functionalities.
from pyspark.sql import SparkSession
# Creating SparkSession (which also provides SparkContext)
spark = SparkSession.builder \
.appName("Spark Example") \
.getOrCreate()
# SparkContext example, accessing through SparkSession
sc = spark.sparkContext
SparkSession.builder.getOrCreate() method
# This returns an existing SparkSession if there's already one in
# the environment, or creates a new one if necessary.
spark = SparkSession.builder \
.appName("Spark Example") \
.getOrCreate()
Catalog
This is a metadata repository within Spark SQL. It keeps track of all the data and metadata (like databases, tables, functions, etc.) in a structured format. The catalog is available via the SparkSession, which is the unified entry point for reading, writing, and configuring data in Spark.
# Lists all the tables inside the cluster
tables_list = spark.catalog.listTables()
print(tables_list)
print([table.name for table in tables_list])
SparkSession.sql() and .show() methods
# This method takes a string containing the query and returns a
# DataFrame with the results
result_df = spark.sql("SELECT * FROM tableName WHERE someColumn > 10")
result_df.show()
.toPandas() method
# Convert Spark DataFrame to pandas DataFrame
pandas_df = result_df.toPandas()
createDataFrame() and .createOrReplaceTempView()
import pandas as pd
# Assuming pandas_df is a pandas DataFrame
spark_df = spark.createDataFrame(pandas_df)
# The DataFrame is now in Spark but not in the SparkSession catalog
spark_df.createOrReplaceTempView("temp_table")
createOrReplaceTempView(): This method is a part of the DataFrame API. When you call this method on a DataFrame, it creates (or replaces if it already exists) a temporary view in the Spark catalog. This view is temporary in that it will disappear if the session that created it terminates. The temporary view allows the data to be queried as a table in Spark SQL.
createOrReplaceTempView()..read.csv() method
# Convert a CSV file to a Spark DataFrame
df = spark.read.csv("path/to/your/file.csv", header=True)
filter method
# Equivalent to WHERE clause in SQL
filtered_df = df.filter(df["some_column"] > 10)
select method
# SELECT clause
selected_df = df.select("column1", "column2")
selectExpr method
# SELECT which takes SQL expressions as input
expr_df = df.selectExpr("column1 as new_column_name", "abs(column2)")
groupBy() and aggregation functions
from pyspark.sql import functions as F
grouped_df = df.groupBy("someColumn").agg(
F.min("anotherColumn"),
F.max("anotherColumn"),
F.count("anotherColumn"),
F.stddev("anotherColumn")
)
SELECT some_column,
MIN(another_column) AS min_another_column,
MAX(another_column) AS max_another_column,
COUNT(another_column) AS count_another_column,
STDDEV(another_column) AS stddev_another_column
FROM df
GROUP BY some_column
.withColumn() and .withColumnRenamed() methods
# Adding a new column or replacing an existing one
new_df = df.withColumn("new_column", df["some_column"] * 2)
# Renaming a column
renamed_df = df.withColumnRenamed("old_name", "new_name")
join method
# Joining two tables
joinedDF = table1.join(table2, "common_column", "leftouter")
.cast() method
# Casting a column to a different type
df = df.withColumn("some_column", df["some_column"].cast("integer"))
Conclusion
In wrapping up our exploration of the basics of Apache Spark, it's clear that this powerful framework stands out for its ability to process large volumes of data efficiently across distributed systems. Spark’s versatile ecosystem, which encompasses Spark SQL, DataFrames, and advanced analytics libraries, empowers data engineers and scientists to tackle a wide array of data processing and analysis tasks. Keep an eye out for future articles in this Spark series, where I'll delve deeper into Spark's architecture, execution models, and optimization strategies, providing you with a comprehensive understanding to leverage its full capabilities.

